本文从产品设计和架构角度分享了Microsoft内存数据库方面的使用经验,希望你在阅读本文之后能够了解这些新的对象、概念,从而更好地设计你的架构。
内存数据库,指的是将数据库的数据放在内存中直接操作。相对于存放在磁盘上,内存的数据读写速度要高出很多,故可以提高应用的性能。微软的SQL Server 2014已于2014年4月1日正式发布,SQL 2014一个主要的功能即为内存数据库。
下面,我将着重介绍使用SQL Server 2014内存数据库时需要注意的地方。
关于内存数据库
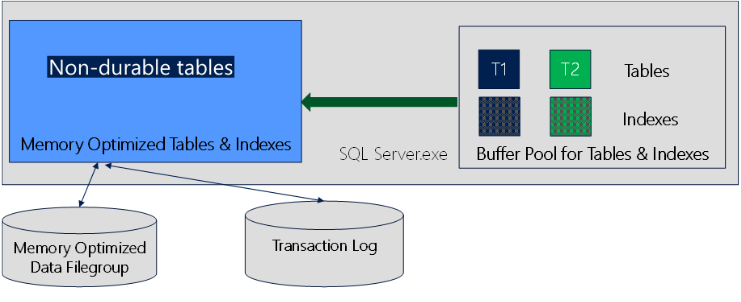
SQL Server 2014内存数据库针对传统的表和存储过程引入了新的结构: memory optimized table(内存优化表)和native stored procedure(本地编译存储过程)。
默认情况下Memory optimized table是完全持久的(即为durable memory optimized table),如传统的基于磁盘的表上的事务一样,并且完全持久的事务也是支持原子、一致、隔离和持久 (ACID) 的。所不同的是内存优化表的整个表的主存储是在内存中,即为从内存读取表中的行,和更新这些行数据到内存中。 并非像是传统基于磁盘的表按照数据库数据库页面装载数据库。内存优化表的数据同时还在磁盘上维护着另一个副本,但仅用于持续性目的。 在数据库恢复期间,内存优化的表中的数据再次从磁盘装载。 创建持久的内存优化表方法如下:
CREATE TABLE DurableTbl
(AccountNo INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 28713)
,CustName VARCHAR(20) NOT NULL
,Gender CHAR NOT NULL /* M or F */
,CustGroup VARCHAR(4) NOT NULL /* which customer group he/she belongs to */
,Addr VARCHAR(50) NULL /* No address supplied is acceptable */
,Phone VARCHAR(10) NULL /* Phone number */
)
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
除了默认持久的内存优化表之外,还支持non-durable memory optimized table(非持久化内存优化表),不记录这些表的日志且不在磁盘上保存它们的数据。 这意味着这些表上的事务不需要任何磁盘 IO,但如果服务器崩溃或进行故障转移,则无法恢复数据。创建非持久化内存优化表方法如下:
CREATE TABLE NonDurableTbl
(AccountNo INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 28713)
,CustName VARCHAR(20) NOT NULL
,Gender CHAR NOT NULL /* M or F */
,CustGroup VARCHAR(4) NOT NULL /* which customer group he/she belongs to */
,Addr VARCHAR(50) NULL /* No address supplied is acceptable */
,Phone VARCHAR(10) NULL /* Phone number */
)
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY)
Native compiled stored procedure(本地编译存储过程)是针对传统的存储过程而言的,是本机编译存储过程后生成DLL,由于本机编译是指将编程构造转换为本机代码的过程,这些代码由处理器指令组成,无需进一步编译或解释。与传统TSQL 相比,本机编译可提高访问数据的速度和执行查询的效率。故通过本机编译的存储过程,可在存储过程中提高查询和业务逻辑处理的效率。创建方法本地编译存储过程方法如下:
CREATE PROCEDURE dbo.usp_InsertNonDurableTbl
@AccountNo int,
@CustName nvarchar(20),
@Gender char(1),
@CustGroup varchar(4),
@Addr varchar(50),
@Phone varchar(10)
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'English')
BEGIN
INSERT INTO [dbo].[DurableTbl]
([AccountNo]
,[CustName]
,[Gender]
,[CustGroup]
,[Addr]
,[Phone])
VALUES (@AccountNo
,@CustName
,@Gender
,@CustGroup
,@Addr
,@Phone)
END
END
GO
内存数据库既可以包含内存优化表和本地编译存储过程,又可以包含基于磁盘的表和传统存储过程,各个对象之间数据存储、和访问的架构如下所示:
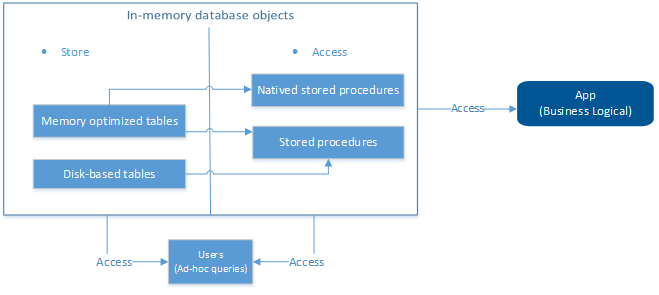
使用场景
传统基于磁盘的表,通常会遇到内存页面置换、死锁、造成了吞吐量有限、事务延迟较长等问题,内存数据库的内存优化表由于常驻内存,适用于低延迟、高并发、快速数据传输和装载等场景。各场景的使用、机制具体如下:
低延迟:由于内存优化表和本地编译存储过程直接生成DLL,本机编译可提高访问数据的速度和执行查询的效率响应速度快,作为参与处理业务逻辑的存储过程而言,大大降低了存储过程作为中间层执行和访问的效率。提高了应用的访问效率,降低了延迟性。
内存优化表的创建和装载过程如下:

本地编译存储过程的创建和装载过程如下:

对于基于磁盘的表和内存优化表,我们可以在以下示例中对比内存优化表:创建两个同样结构的表,一个为基于磁盘的表包含1700万条记录,当使用常规存储过程查询一条记录,查询时间为67ms;
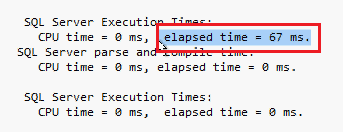
另一个为内存优化表包含1亿条记录。当使用本地编译存储过程查询内存优化表,所需的执行时间不到1毫秒。
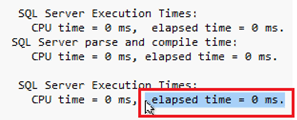
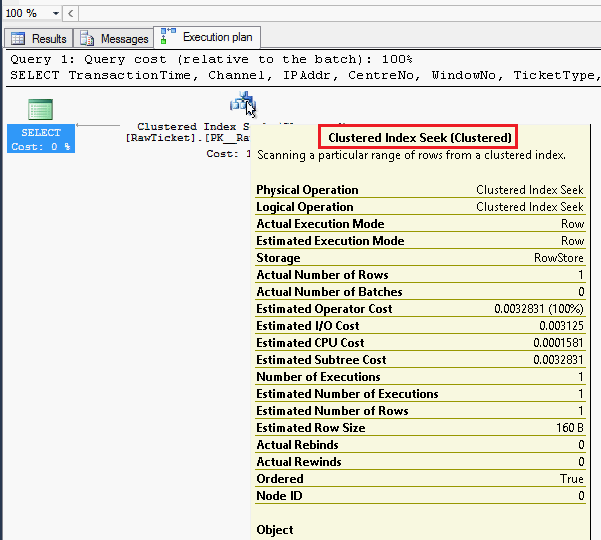
当我们进一步查看两个存储过程的执行计划,发现第一个已经使用聚集索引检索,第二个本地编译存储过程如所预期的,是基于内存优化表的索引检索。
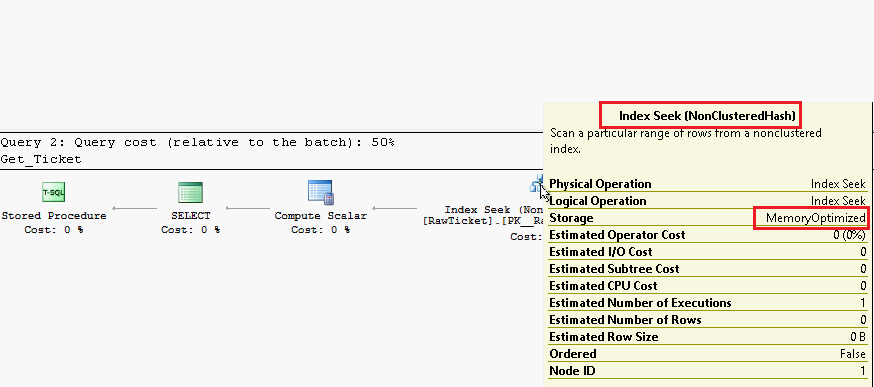
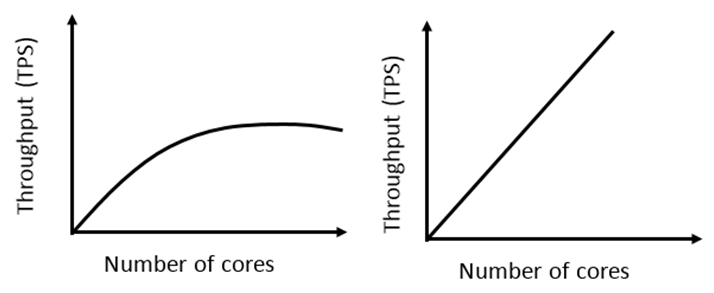
高吞吐量:由于内存优化表直接从内存中读取、写入数据,当访问数据时,不再使用latch,故不同于基于磁盘的表,对于insert/update/delete的操作,latch争用、以及死锁问题随即消失。
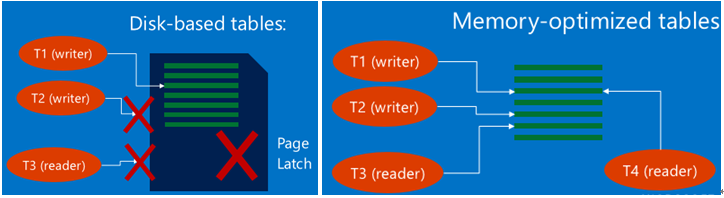
与此同时,可大大提高了应用的吞吐量。 随着配置的增加,其性能呈直线上升。
快速数据传输、装载: 由于非持久化内存优化表仅常驻内存,并无基于磁盘的副本。当需要将一些外部数据通过ETL装载到内存数据库,可以使用无任何IO和logging的非持久化内存优化表作为过渡表,可有效的加快装载数据库的速度。
内存数据库设计与性能
并非所有的场景都可以利用到OLTP的内存数据库的优势,针对符合内存数据库使用场景的需求,需确定哪些对象适合转化为内存优化表和本地编辑存储过程,对于已经存在的系统的表对象,如何迁移这些对象。
选择合适的内存优化表
SQL Server 2014 提供了AMR即为Analysis, Migration and Reporting,此工具可来检测哪些基于磁盘的表和存储过程适合迁移到内存数据库中。下面的流程图给出了建议的工作流程:
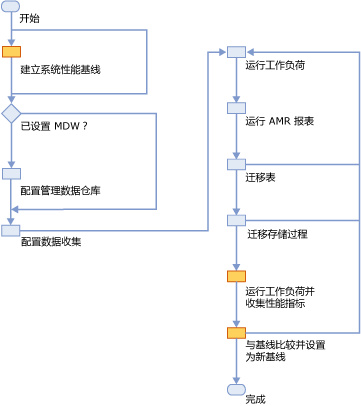
经常用于做为核心基线的一些指标如下:
-
SQL Server 的 CPU 占用率。
-
SQL Server 的内存占用率。
-
SQL Server 的 I/O 活动。
-
处理事务时,实例的事务吞吐量。
当已经确定哪些表需要调整为内存优化表,可针对内存优化顾问的“表内存优化顾问”所列出来的清单一一调整,且评估每个表对内存的使用量。
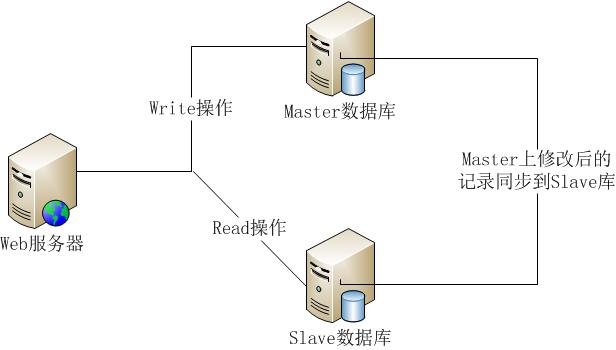
通常在实际生产环境中,为了保证服务的高可用性和数据的完整性、安全性,几乎很少有数据库为单实例结构,紧接着面临的问题是,如何实现内存数据库的高可用性。
内存数据库的高可用性
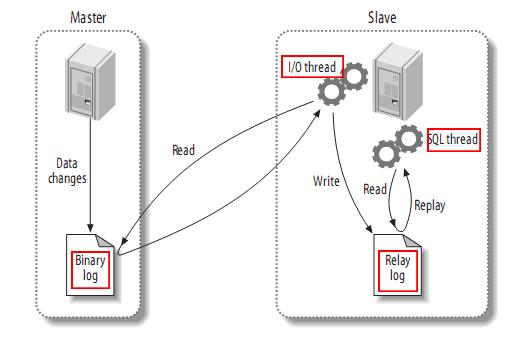
SQL 2014的内存数据库与现在有诸如群集、Alwayson、replication等高可用技术完全集成,故基于内存数据库的基础上,搭建SQL Server Alwayson Availability Group,考虑到同一数据中心带宽和网络延迟优于跨数据中心,可在同一数据中心采用同步模式作为高可用,不同数据库中心采用异步模式作为灾备。架构如下:
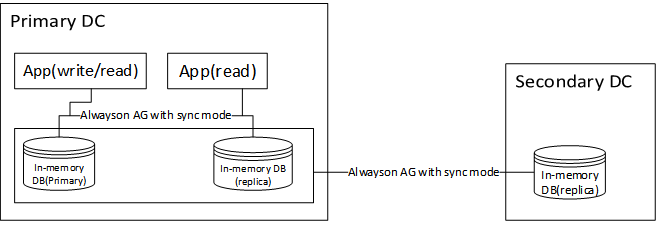
由于内存数据库本身常驻内存,在设计架构时需要注意不同高可用的局限性:
群集:考虑到数据库服务的高可用性,传统基于磁盘的数据库经常采用数据库群集保证应用服务的不间断性。同样内存数据库适用于数据库群集,故Active/Passive、Active/Active、以至于M/N(多个活动节点/多个被动节点)模式的群集均可考虑内存数据库,所需注意的是:
-
在故障切换时,由于内存优化表需要将所有数据装载到内存中,切换时间比基于磁盘的表时间略长。
-
非持久性内存优化表由于磁盘并未存放数据副本,在故障切换时,数据内容会被清空。
Alwayson: 在SQL 2012中出现的新功能Alwayson availability group可为数据库提供多个同步或者异步的数据库副本, 在SQL 14中内存数据库与Alwayson availability group可完全集成。依赖于Alwayson的部署向导,内存数据库可像传统数据库一样,快速加入Alwayson availability group中,所需注意的是:
-
在切换主从数据库时,切换时间较快,由于依赖于alwayson的事务日志记录的redo进程,无需从磁盘重新装载数据库到内存中。
-
若内存数据库中包含非持久性内存优化表,由于无法依赖于事务日志,非持久性内存优化表的数据仅存在于primary节点。
通常Alwayson也被使用于本地数据库的高可用性,和异地数据库的灾备场景,与内存优化表的结合在性能上,对于主从节点之间网络延迟、传递的事务的大小、以及内存数据库所在的磁盘是否较快,均可影响其性能。
Replication: 复制是将数据和数据库对象从一个数据库复制和分发到另一个数据库,然后在数据库之间进行同步以保持一致性的一种技术。内存数据库中的内存优化表可作为单向事务性复制的订阅方,所需注意的是:
-
内存优化表的行数据限制在8060 bytes一下。
-
复制订阅方的数据类型要遵循内存优化表的限制。
数据库架构设计
由于持久性内存优化表需要在服务启动时,将数据装载到内存中,这涉及对现有RTO有一定量的影响。在设计内存数据库文件组的架构时,需注意完全持久的内存优化表的大小、以及装载数据的速度。
在由架构和业务数据量确定内存优化表的大小的前提下,可通过多个Container提升内存数据库的数据装载的速度。
由于每个Container包含着检查点文件对(Checkpoint File Pairs 即为CFPs),CFP 由数据文件和差异文件构成,内存优化表中的数据存储在 CFP 中。为提高数据库服务启动时RTO,在为内存优化数据库创建多个container时,可并行处理不同Container内的检查点文件对,即为提高装载数据到内存数据库的速度。
例如创建Container可在创建数据库时创建,或者一个或多个container添加到 MEMORY_OPTIMIZED_DATA 文件组,脚本如下所示:
CREATE DATABASE InMemory_DBTest ON
PRIMARY (NAME = [InMemory_DB_hk_fs_data], FILENAME = 'D:\InMemory_DBTest\InMemory_DB_data.mdf'),
FILEGROUP [InMemory_DB_fs_fg] CONTAINS MEMORY_OPTIMIZED_DATA
(NAME = [InMemory_DB_fs_dir], FILENAME = 'D:\ InMemory_DBTest\ InMemory_DB_hk_fs_dir'),
(NAME = [InMemory_DB_fs_dir2], FILENAME = 'D:\ InMemory_DBTest\ InMemory_DB_hk_fs_dir2'),
(NAME = [InMemory_DB_fs_dir3], FILENAME = 'D:\ InMemory_DBTest\ InMemory_DB_hk_fs_dir3')
LOG ON (name = [test_log], Filename='D:\ InMemory_DBTest\ InMemory_DB.ldf', size=100MB)
COLLATE Welsh_100_BIN2
Go
此外,并在不同的驱动器上分配这些Container,以实现更多带宽来将数据传输到内存中。由于内存数据库引擎会根据轮询法跨Container分发数据文件和差异文件,为提高Container对磁盘的带宽的性能,应在每个磁盘均衡数据文件和差异文件。
对于设计内存优化表时,需要考虑bucket的数量,一般来讲建议bucket的数量为预估表记录的1-2倍。
相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能。由于内存数据库是以牺牲内存资源为代价换取数据处理实时性的,以下图表显示了近些年计算机硬件(内存)飞速发展,为内存数据库的使用带来了可能性。
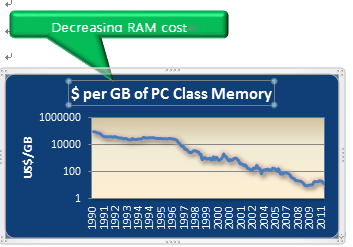
内存数据库在使用硬件资源与传统表有着一定的特殊性,为了提高内存数据库性能,对存储内存数据库的各方面的资源有着比传统数据库更高的要求。可参考如下具体需求:
内存:所有内存优化表是常驻内存的,因此需足够的物理内存来存储内存优化表。但这并不意味着需要将整个数据库放入内存中,而是仅将频繁访问的热数据常驻内存优化表中。且最高可以支持到256GB的数据量。
可使用如下脚本查看内存优化表的内存使用量:
select object_name(object_id), * from sys.dm_db_xtp_table_memory_stats
磁盘:同样存在log和data两类文件。Log文件依然记录事务信息。针对于持久性的内存优化表,为了降低log IO的竞争、保证低延迟,一般建议至少SSD。
CPU: 可根据OLTP环境的负载考虑CPU的配置,如两个CPU socket支撑一个中等级别的服务器。
Network: 针对于单机的内存数据库,由于数据存储于数据库服务器的内存中,对于数据交互仍然为应用层到数据层的访问,如以往数据交互,对于网络并未有较高的依赖性。对于内存数据库应用于数据库高可用和异地灾备的情况下(如同步/异步模式的Always-on),同一数据中心的网络延迟,以及不同数据中的网络延迟对于使用与高可用性和灾备的内存数据库的事务有一定量的影响。
维护管理内存数据库
由于内存数据库对内存有着较大的依赖,在管理内存方面,可以考虑使用Resource governor来管理内存数据库。需注意如下:
-
通过指定Resource governor的hard limit(如80%)来确保其它内部资源和非内存优化表的内存使用量。
-
每个resource pool可以包含多个内存数据库,但是一个内存数据库在同一时刻只关联一个resource pool。
Memory Usage Report是SSMS自带的监控内存使用量的报表,可以快速的查看现有缓存的内存优化对象的使用情况:
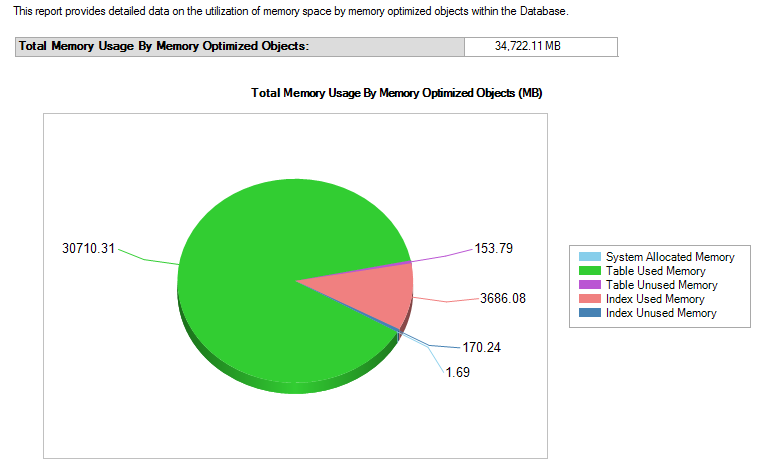
备份在日常维护管理数据库中也极为重要,对持久性内存优化表,内存优化表作为数据库对象中的一部分,被包含在常规数据库备份策略中,故传统的全备、差异备份、日志备份策略无需更改,即可实现对内存优化表的备份。
...