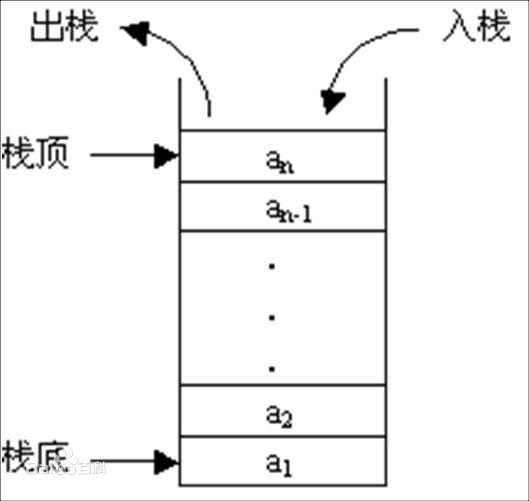
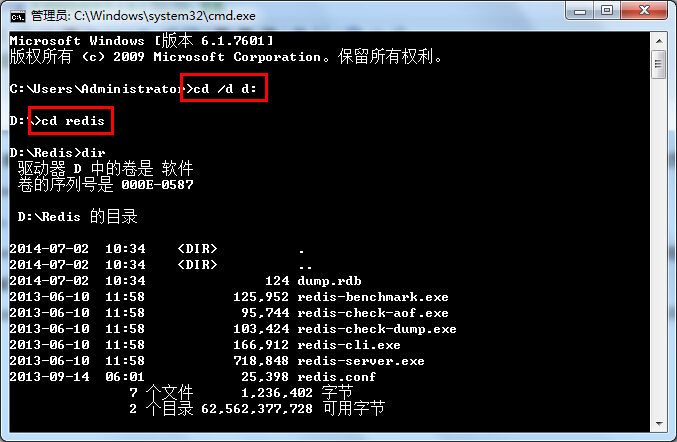
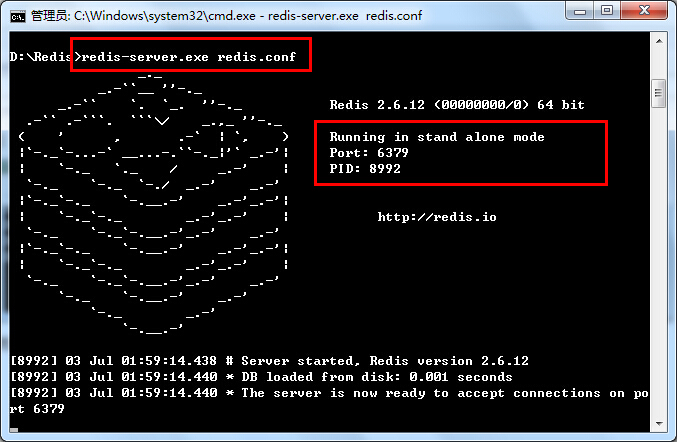
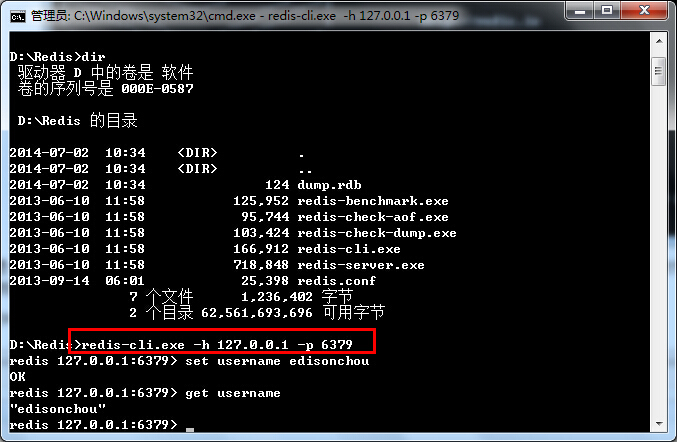
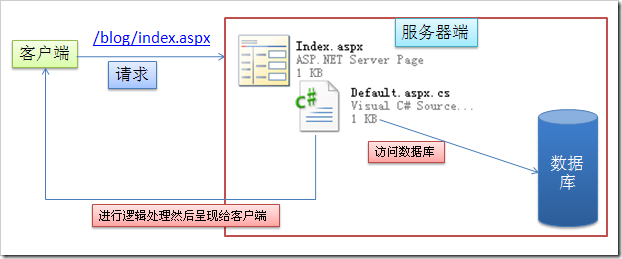
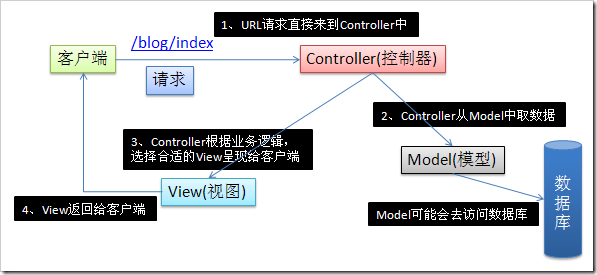
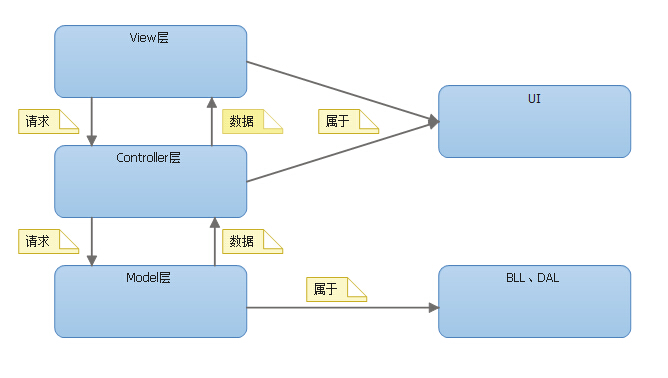
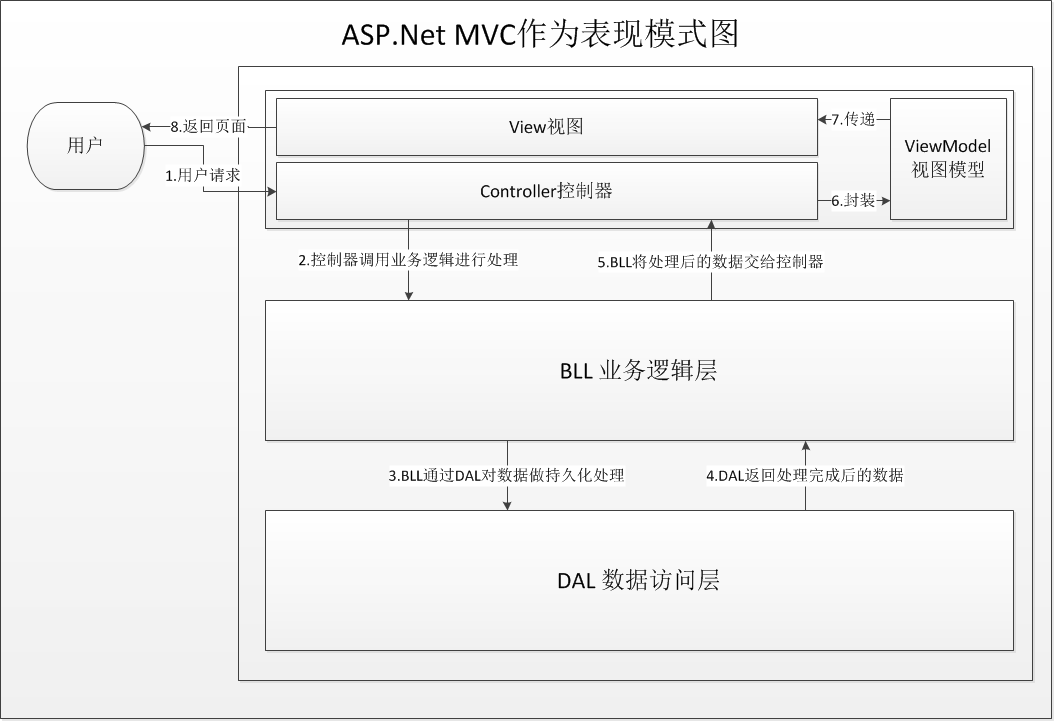
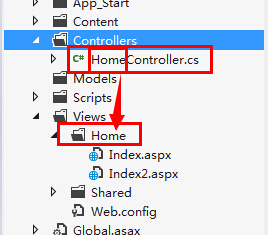
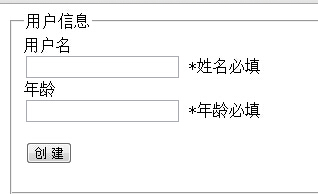
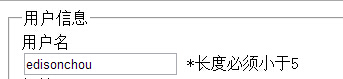
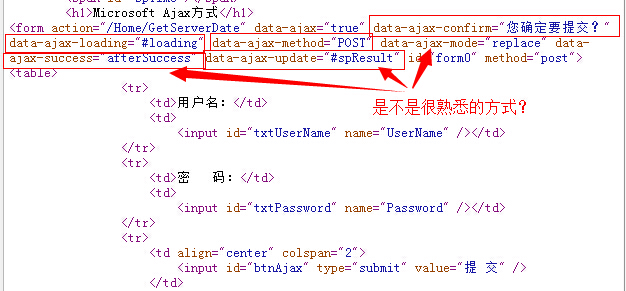
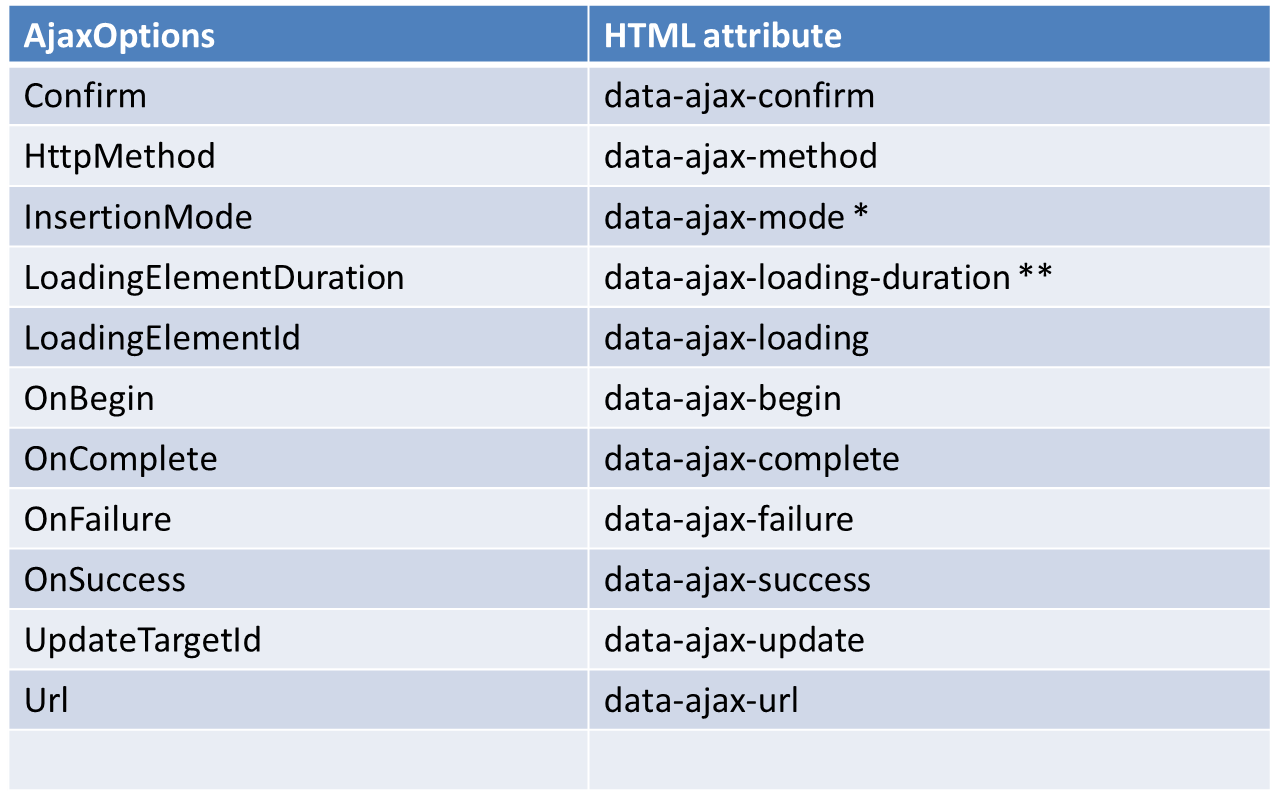
一、天降神器“剃须刀” — Razor视图引擎

1.1 千呼万唤始出来的MVC3.0
在MVC3.0版本的时候,微软终于引入了第二种模板引擎:Razor。在这之前,我们一直在使用WebForm时代沿留下来的ASPX引擎或者第三方的NVelocity模板引擎。
Razor在减少代码冗余、增强代码可读性和Visual Studio智能感知方面,都有着突出的优势。Razor一经推出就深受广大ASP.Net开发者的喜爱。
1.2 Razor的语法
(1)Razor文件类型:Razor支持两种文件类型,分别是.cshtml 和.vbhtml,其中.cshtml 的服务器代码使用了c#的语法,.vbhtml 的服务器代码使用了vb.net的语法。
(2)@字符:@是Razor中的一个重要符号,它被定义为Razor服务器代码块的开始符号。例如,我们可以在View中直接写C#代码输出日期
1 <p>@DateTime.Now.ToString()</p>
1.3 Razor语句块
(1)在Razor视图引擎中,我们可以使用@{code}来定义一段代码块。
(2)Razor支持代码混写:在代码块中插入HTML、在HTML中插入Razor语句都是可以的。例如,我们可以使用@来作for循环,还可以进行if判断
@for (int i = 0; i < 10; i++)
{
<p>@i</p>
}
@if (ViewData.Count > 0)
{
<p>ViewData有数据</p>
ViewData["Key"] = "Edison Chou";
}
else
{
<p>ViewData暂无数据</p>
}
1.4 Razor页面输出特殊字符串
与在ASPX试图引擎中类似,如果要输出特殊字符串,还是借助HtmlHelper类提供的扩展方法来实现。
(1)输出原生的字符串:@Html.Raw(html)
@Html.Raw("<h1>Razor</h1>")
PS:默认的@会解析掉html代码
(2)还可以通过使用HtmlString类型和MvcHtmlString类型字符串输出原生包含HTML的字符串
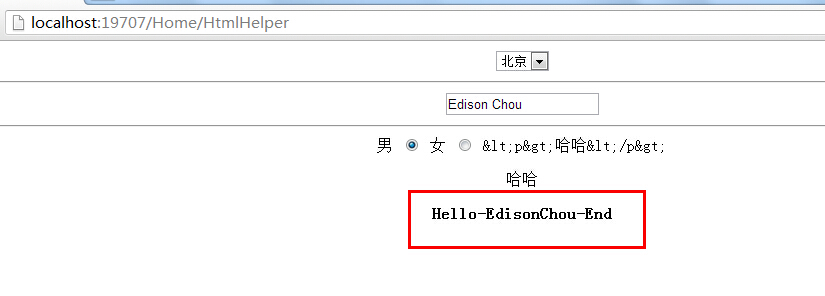
@{
IHtmlString html = new HtmlString("<span style='color:red'>哈哈,我是Razor剃须刀!</span>");
Response.Write(html);
}
1.5 Razor中的注释
Razor服务器端注释为:@* 注释内容 *@
1.6 Razor中转换数据类型
在Razor中提供了很多方便我们进行数据类型转换的方法以及类型判断的方法,如下图所示:

例如,我们可以在View中对一个字符串进行判断和转换:
@{
string test = "Edison Chou";
<p>@test.IsInt()</p>
<p>@test.AsInt()</p>
}
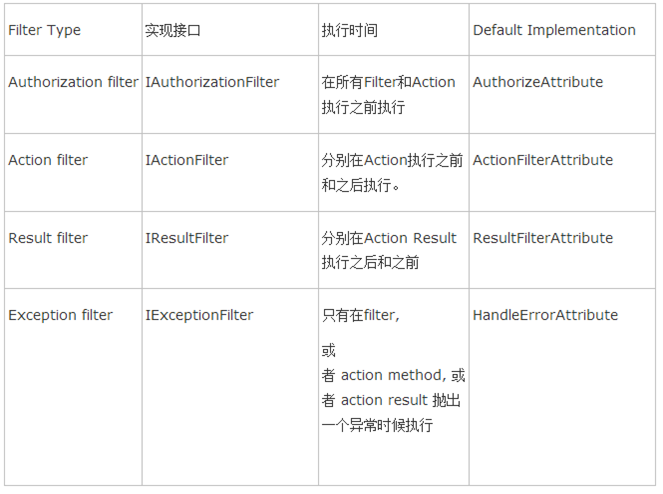
二、Controller深入详解
2.1 控制器的三个职责
(1)处理跟用户的交互
(2)处理业务逻辑的调用
(3)指定具体的视图显示数据,并且把数据传递给视图
2.2 控制器的三个约定

(1)必须是非静态类
(2)必须实现IController接口
(3)必须是以Controller结尾命名
2.3 无所不能的Action
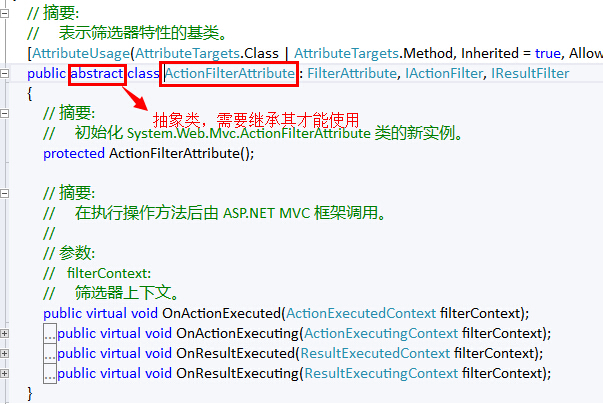
首先,在一个Controller中可以包含多个Action. 每一个Action都是一个方法, 返回一个ActionResult实例。那么,这个ActionResult是什么东东呢?
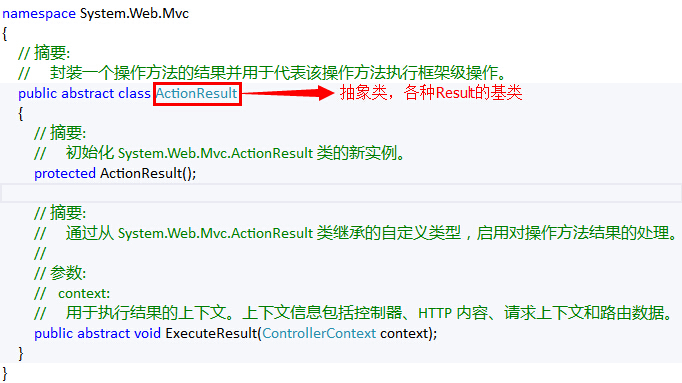
由微软给出的注释可以知道,ActionResult是一个操作方法的结果,并且是一个抽象类,那么,也就代表了可以有多重结果的实现。这样就解释了,我们在Action中可以不仅可以返回ViewResult还可以返回JsonResult的原因。通过下表,我们可以清晰地看到,ActionResult的各种派生类的详情:
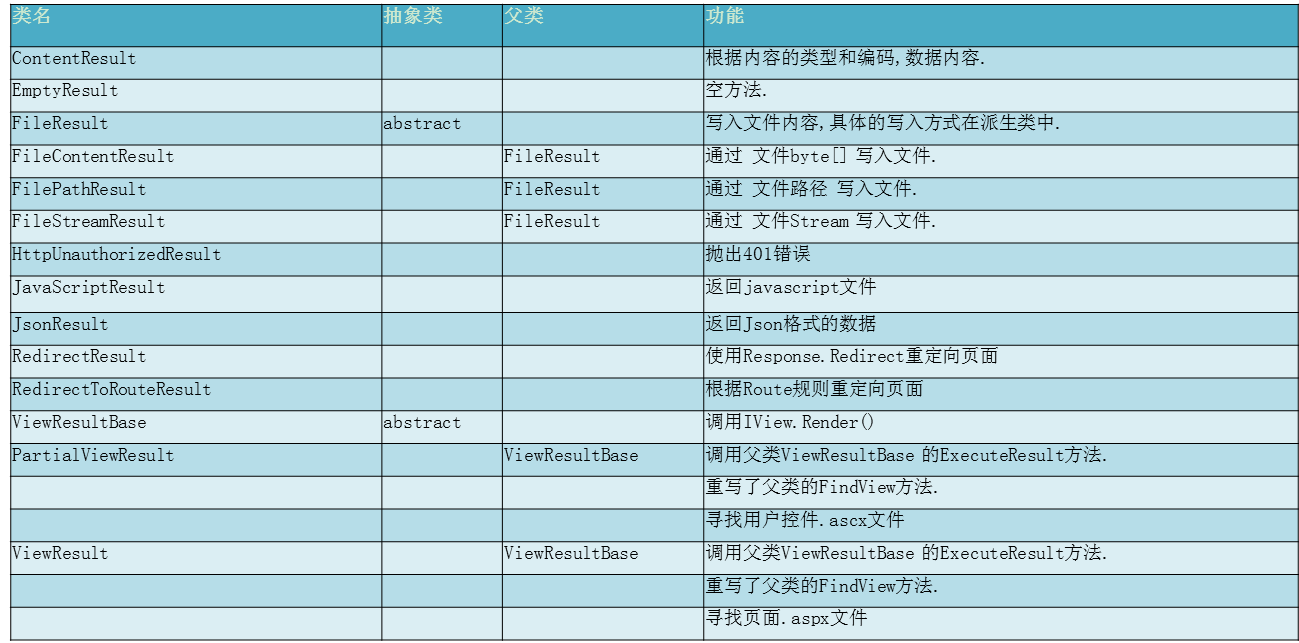
从表中可以看出,我们所常用的各种XXXXResult都不约而同地继承了ActionResult这个基类,或者是其父类(例如:ViewResultBase)继承了ActionResult这个基类。因此,我们既可以在Action中返回视图,还可以返回文件流、重定向、空内容等结果。特别是,以前我们在WebForm时代常常与浏览器交互采用JSON格式的数据,需要使用JavaScriptSerializer这个类进行Serialize后返回。但是,在MVC的Action中,微软已经帮我们封装了好了JsonResult,因此,我们可以高兴地感慨:返回Json,So Easy!
2.4 ActionResult用法
这里只介绍几个最常用的Result用法:
(1)EmptyResult:当用户有误操作或者是图片防盗链的时候,这个EmptyResult就可以派上用场,返回它可以让用户啥也看不到内容,通过访问浏览器端的源代码,发现是一个空内容;
public ActionResult Empty()
{
return new EmptyResult();
}
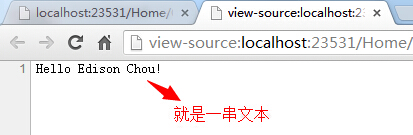
(2)Content:通过Content可以向浏览器返回一段字符串类型的文本结果,就相当于Response.Write("xxxx");一样的效果;
public ActionResult ContentResultDemo()
{
string contentString = "Hello Edison Chou!";
return Content(contentString);
}
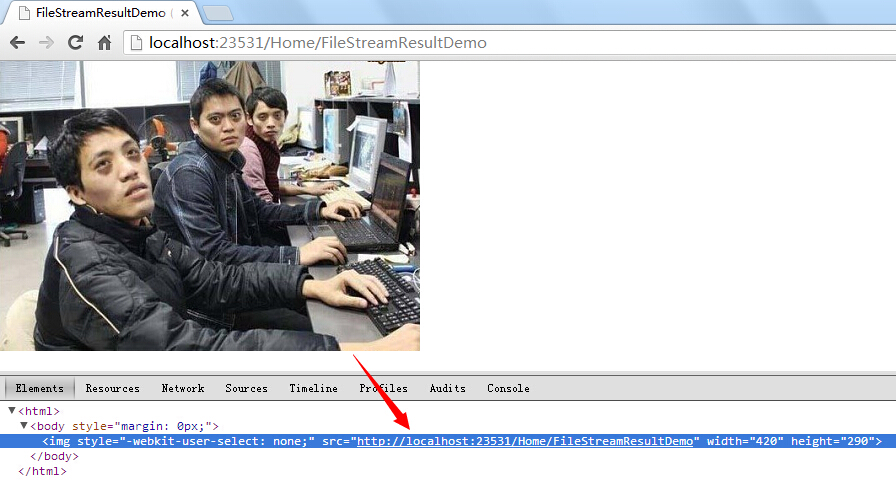
(3)File:通过File可以向浏览器返回一段文件流,主要用于输出一些图片或文件提供下载等;
public ActionResult FileStreamResultDemo()
{
FileStream fs = new FileStream(Server.MapPath(@"/Content/programmer.jpg"),
FileMode.Open, FileAccess.Read);
return File(fs, @"image/gif");
}
(4)HttpUnauthorizedResult:通过HttpUnauthorizedResult可以向浏览器输出指定的状态码和状态提示,如果不指定状态码,则默认为401无权访问;
public ActionResult HttpUnauthorizedResultDemo()
{
return new HttpUnauthorizedResult();
}
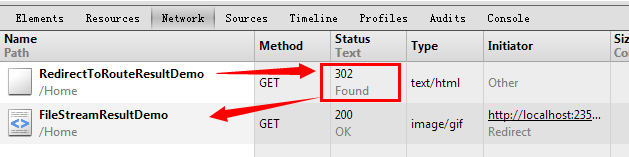
(5)Redirect与RedirectToAction:重定向与重定向到指定Action,我一般使用后者,主要是向浏览器发送HTTP 302的重定向响应;
public ActionResult RedirectResultDemo()
{
return Redirect(@"http://localhost:23531/Home/ContentResultDemo");
}
public ActionResult RedirectToRouteResultDemo()
{
return RedirectToAction("FileStreamResultDemo", "Home");
}
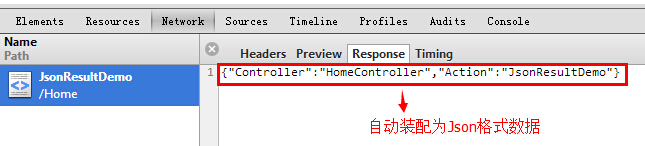
(6)Json:通过Json可以轻松地将我们所需要返回的数据封装成为Json格式,进行Ajax开发可以变得so easy!
public ActionResult JsonResultDemo()
{
var tempObj = new { Controller = "HomeController", Action = "JsonResultDemo" };
return Json(tempObj, JsonRequestBehavior.AllowGet);
}
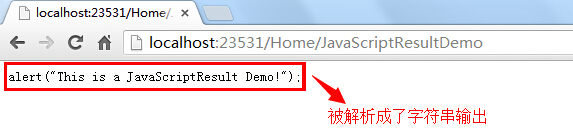
(7)JavaScript:可以通过JavaScriptResult向浏览器单独输出一段JS代码,不过由于主流浏览器都对此进行了安全检查,因此你的JS代码也许无法正常执行,反而是会以字符串的形式显示在页面中;
三、Routing深入详解
首先,ASP.Net MVC项目是URL请求驱动的,为什么访问localhost/home/index会传递给HomeController中名为index的action(即HomeController类中的index方法)?下面,我们一一来看下。
3.1 Routing的作用
假如有一个请求:localhost/home/index,那么路由需要做的事情如下:
(1)确定Controller
(2)确定Action
(3)确定其他参数
(4)根据识别出来的数据,将请求传递给Controller和Action
3.2 神奇的路由规则
根据路由的作用,我们可以知道它是一个“指路人”,指示我们的请求应该到达哪个Controller中的Action。那么,它是根据什么规则来指路的呢?我们可以在App_Start文件夹中的RouteConfig类中找到这个神奇的规则是如何制定的。
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
}
(1)首先,第一句routes.IgnoreRoute代表对所有axd的资源访问请求进行忽略,直接进行URL访问;这里可以阅读参考资料第(5)篇,了解其详细含义,这里就不再赘述;
(2)然后,第二句开始使用MapRoute方法对整个网站定义了一个路由识别规则,这个规则的name是Default,url规则为:{controller}/{action}/{id}。例如我们要访问的URL为:localhost/home/index,在这个URL中,localhost是域名, 所以首先要去掉域名部分: home/index,也是就对应了上面代码中的这种URL结构: {controller}/{action}/{id}。正是因为我们建立了这种URL结构的识别规则,,所以能够识别出 Controller是home, action是index, id没有则为默认值""。
(3)在MapRoute方法中为所有URL请求定义了一个defaults默认值:controller为空则指向Home,action为空则指向Index,而id则是可选的,非必须要的。
这里,对于路由规则需要注意的有两点:
(1)可以有多条路由规则;
(2)路由规则是有顺序的(前面的规则被匹配后,后面的规则就不再匹配);
我们可以在RegisterRoutes这个方法中添加一条自定义路由规则,并取名为Default2,具体规则代码如下:
routes.MapRoute(
name: "Default2",
url: "{controller}-{action}-{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
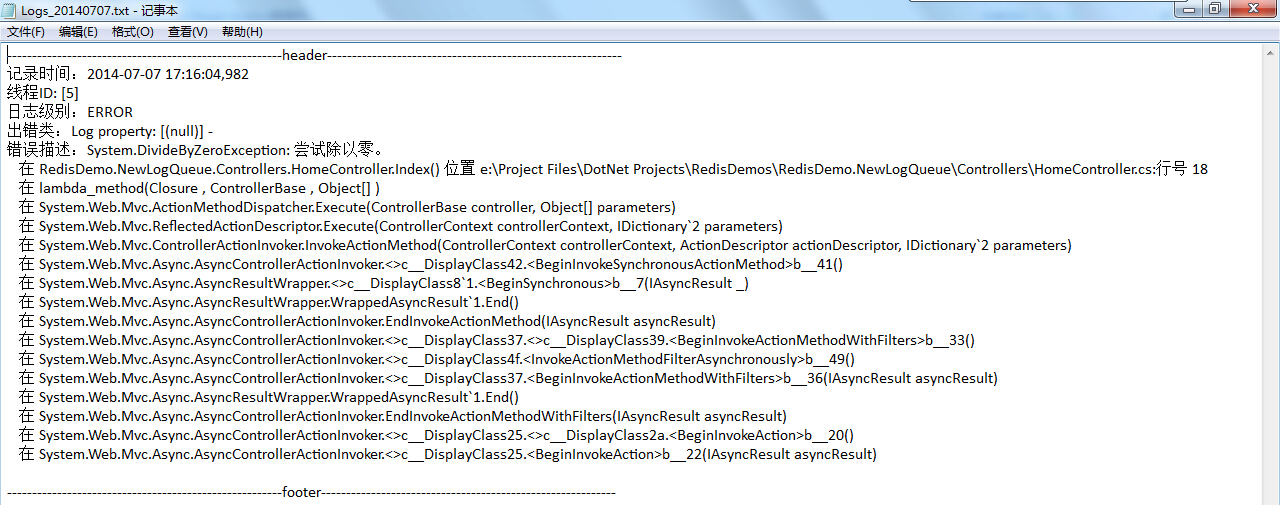
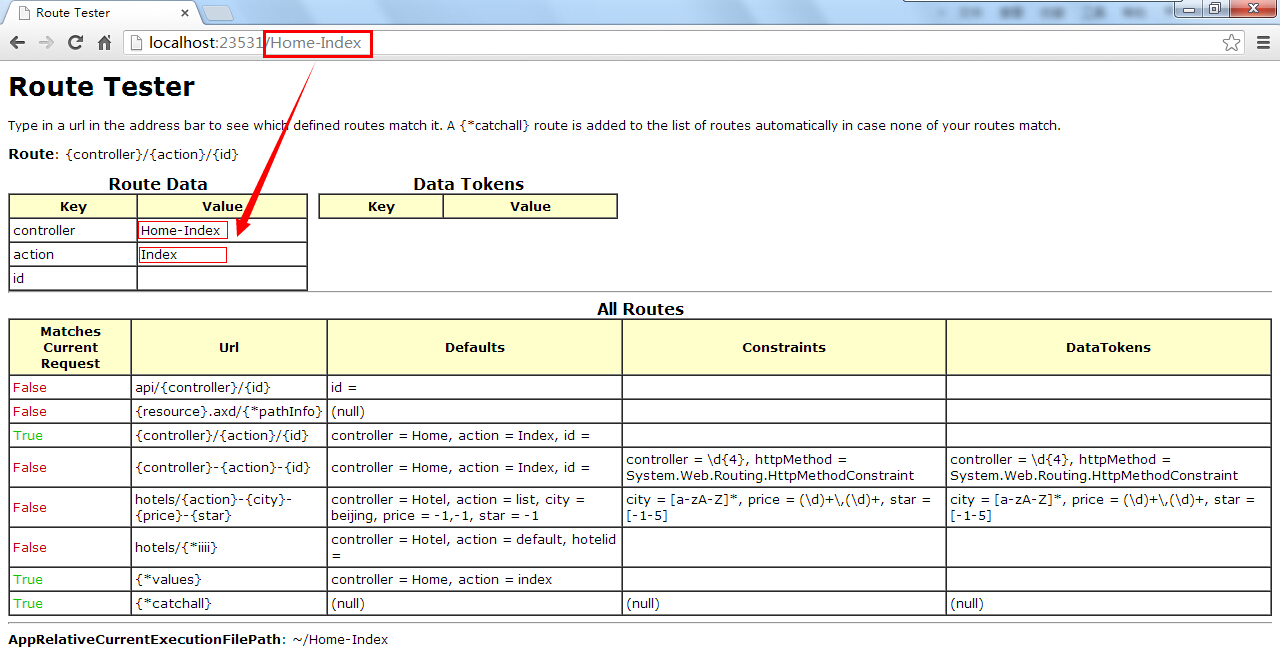
这下如果我们以:localhost/Home-Index来访问时,我们原本想要的是根据Default2这个路由规则访问Home控制器下的Index这个Action,但却被告知以404提示:
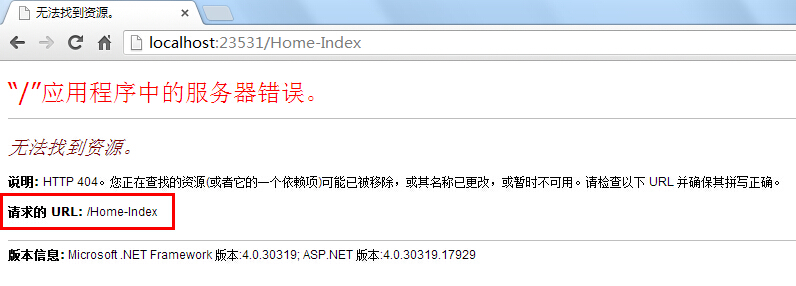
这是为什么呢?我们再来看看RegisterRoutes这个方法:
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
routes.MapRoute(
name: "Default2",
url: "{controller}-{action}-{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
}
我们刚刚提到,路由规则是有顺序的(前面的规则被匹配后,后面的规则就不再匹配)。那么,可以推断,由于Default2在Default之后,有可能我们的请求localhost/Home-Index已经被Default这个规则所匹配了,因此Default2规则根本没有出场Show一下。那么,在Default规则中,它将Home-Index作为Controller的名字匹配,去访问Home-Index这个Controller,而Action使用默认的Index,那么它所请求的应该是这个URL:/localhost/Home-Index/Index。由于网站中,并没有Home-Index这个Controller,所以也就出现了刚刚那个404页面。
3.3 MapRoute方法介绍
(1)MapRoute方法提供了以下几种方式的重载:
MapRoute( string name, string url);
MapRoute( string name, string url, object defaults);
MapRoute( string name, string url, string[] namespaces);
MapRoute( string name, string url, object defaults, object constraints); MapRoute( string name, string url, object defaults, string[] namespaces);
MapRoute( string name, string url, object defaults, object constraints, string[] namespaces);
我们在上面所使用的便是第二种重载。
(2)MapRoute方法参数详细介绍:
①name参数:
规则名称, 可以随意起名。不可以重名,否则会发生错误: “路由集合中已经存在名为“Default”的路由。路由名必须是唯一的”。
②url参数:
url获取数据的规则,这里不是正则表达式,将要识别的参数括起来即可,比如: {controller}/{action}
最少只需要传递name和url参数就可以建立一条Routing(路由)规则,比如实例中的规则完全可以改为:
routes.MapRoute( "Default", "{controller}/{action}");
③defaults参数:
url参数的默认值:如果一个url只有controller: localhost/home/,而且我们只建立了一条url获取数据规则: {controller}/{action},那么这时就会为action参数设置defaults参数中规定的默认值。由于defaults参数是Object类型,所以可以传递一个匿名类型来初始化默认值:new { controller = "Home", action = "Index" }。
在ASP.Net MVC网站默认实例中使用的是三个参数的MapRoute方法:
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional }
);
④constraints参数:
用来限定每个参数的规则或Http请求的类型。constraints属性是一个RouteValueDictionary对象,也就是一个字典表,但是这个字典表的值可以有两种类型:
一是:用于定义正则表达式的字符串(正则表达式不区分大小写)。通过使用正则表达式可以规定参数格式,比如controller参数只能为4位数字:new { controller = @"\d{4}"}
routes.MapRoute(
name: "Default2",
url: "{controller}-{action}-{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional },
constraints: new { controller = @"\d{4}" }
);
二是:一个用于实现 IRouteConstraint 接口且包含Match方法的对象。
例如:通过第IRouteConstraint 接口可以限制请求的类型(是GET还是POST)。因为System.Web.Routing中提供了HttpMethodConstraint类,,这个类实现了IRouteConstraint 接口。
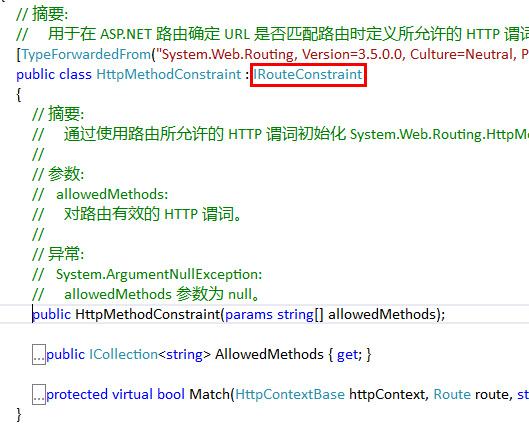
我们可以通过为RouteValueDictionary字典对象添加键为"httpMethod", 值为一个HttpMethodConstraint对象来为路由规则添加HTTP 谓词的限制,比如限制一条路由规则只能处理GET请求:httpMethod = new HttpMethodConstraint( "GET" )
routes.MapRoute(
name: "Default2",
url: "{controller}-{action}-{id}",
defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional },
constraints: new {
controller = @"\d{4}",
httpMethod = new HttpMethodConstraint("GET") }
);
3.4 URL路由实例详解
一般来说,对于一个网站为了SEO友好,网址的URL层次最好不要超过三层:localhost/{频道}/{具体网页},其中域名第一层, 频道第二层, 那么最后的网页就只剩下最后一层了。如果使用默认实例中的“{controller}/{action}/{其他参数}"的形式则会影响网站的SEO。
假设我们有一个综合型服务网站,其中有租房频道、酒店频道、KTV频道、电影院频道等等。我们应该怎样来设计URL路由规则呢?
(1)首先,我们知道:可以有多条路由规则,但是路由规则是有顺序的(前面的规则被匹配后,后面的规则就不再匹配);所以,我们可以定义多条路由规则,粒度细的模块(比如:具体的酒店列表页面)路由规则放最前面,粒度粗的模块(比如:门户网站的首页)路由规则放在最后面。
(2)其次,根据模块粒度划分层次结构,以粒度粗细排序为:网站首页->频道首页->具体内容;
(3)最后,我们可以看一个具体的URL路由实例来分析一下:
// 酒店列表页匹配
routes.MapRoute(
"酒店列表页",
"hotels/{action}-{city}-{price}-{star}",
new { controller = "Hotel", action = "list", city = "beijing", price = "-1,-1", star = "-1" },
new { city = @"[a-zA-Z]*", price = @"(\d)+\,(\d)+", star = "[-1-5]" }
);
// 酒店频道所有匹配
routes.MapRoute(
"酒店首页",
"hotels/{*iiii}",
new { controller = "Hotel", action = "default", hotelid = "" }
);
// 网站首页默认匹配
routes.MapRoute(
"网站首页",
"{*values}",
new { controller = "Home", action = "index" }
);
(4)我们可以分析一下上面的路由规则所实现的功能:
①访问 www.mywebsite.com/hotels/list-chengdu-100,200-3 会访问酒店频道的列表页,并传入查询参数(price为100,200,star为3);
②访问 www.mywebsite.com/hotels 下面的任何其他页面地址,都会跳转到酒店首页;
③访问 www.mywebsite.com 下面的任何地址,如果未匹配上面2条,则跳转到首页;
(5)根据上面的规则和实现的功能,我们可以做一个简单的总结如下:
①Routing规则有顺序(按照添加是的顺序),如果一个url匹配了多个路由规则,则按照第一个匹配的路由规则执行。
②由于上面的规则,要将具体频道的具体页面放在最上方,将频道首页 和 网站首页 放在最下方。
③{*values}表示后面可以使用任意的格式。
3.5 URL路由调试
在ASP.Net MVC中,默认是不允许对路由规则进行调试的。但是,我们可以通过使用RouteDebug来辅助进行调试。
(1)首先,我们下载RouteDebug.dll到我们的项目中,并添加对其的引用。
(2)其次,在Global.asax中的Application_Start方法中添加一句代码:
RouteDeug.RouteDebugger.RewriteRoutesForTesting(RouteTable.Routes);
protected void Application_Start()
{
AreaRegistration.RegisterAllAreas();
WebApiConfig.Register(GlobalConfiguration.Configuration);
FilterConfig.RegisterGlobalFilters(GlobalFilters.Filters);
RouteConfig.RegisterRoutes(RouteTable.Routes);
BundleConfig.RegisterBundles(BundleTable.Bundles);
RouteDeug.RouteDebugger.RewriteRoutesForTesting(RouteTable.Routes);
}
(3)最后,F5调试运行,我们请求localhost/Home-Index这个URL时,可以清楚地发现,系统将Home-Index匹配了第一条默认路由规则,也就是将Home-Index作为Controller的名称进行匹配,这也就证明了为什么我们输入这个请求不会匹配第二条Default2的路由规则出现刚刚那个404页面了。
参考资料
(1)马伦,《ASP.Net MVC视频教程》,http://bbs.itcast.cn/thread-26722-1-1.html
(2)葡萄城控件技术团队,《ASP.NET MVC 5—控制器》,http://www.cnblogs.com/powertoolsteam/p/aspnet-mvc5-controller.html
(3)李亮,《ASP.Net MVC3 Controller》,http://www.cnblogs.com/wlitsoft/archive/2012/05/28/2520799.html
(4)顾里江,《ActionResult解析》,http://blog.csdn.net/gulijiang2008/article/details/7642213
(5)紫鱼Tiler,《MVC路由中routes.IgnoreRoute》,http://www.cnblogs.com/flyfish2012/archive/2013/02/01/2889184.html
(6)Capricornus,《路由匹配检测组件RouteDebug.dll》,http://www.cnblogs.com/Capricornus/archive/2010/08/26/1808907.html
...